tl;dr: We learn to solve camera rotation and spatial sound localization tasks solely through self-supervision from multi-view egocentric data
Abstract
The images and sounds that we perceive undergo subtle but geometrically consistent changes as we rotate our heads. In this paper, we use these cues to solve a problem we call Sound Localization from Motion (SLfM): jointly estimating camera rotation and localizing sound sources. We learn to solve these tasks solely through self-supervision. A visual model predicts camera rotation from a pair of images, while an audio model predicts the direction of sound sources from binaural sounds. We train these models to generate predictions that agree with one another. At test time, the models can be deployed independently. To obtain a feature representation that is well-suited to solving this challenging problem, we also propose a method for learning an audio-visual representation through cross-view binauralization: estimating binaural sound from one view, given images and sound from another. Our model can successfully estimate accurate rotations on both real and synthetic scenes, and localize sound sources with accuracy competitive with state-of-the-art self-supervised approaches.
Method
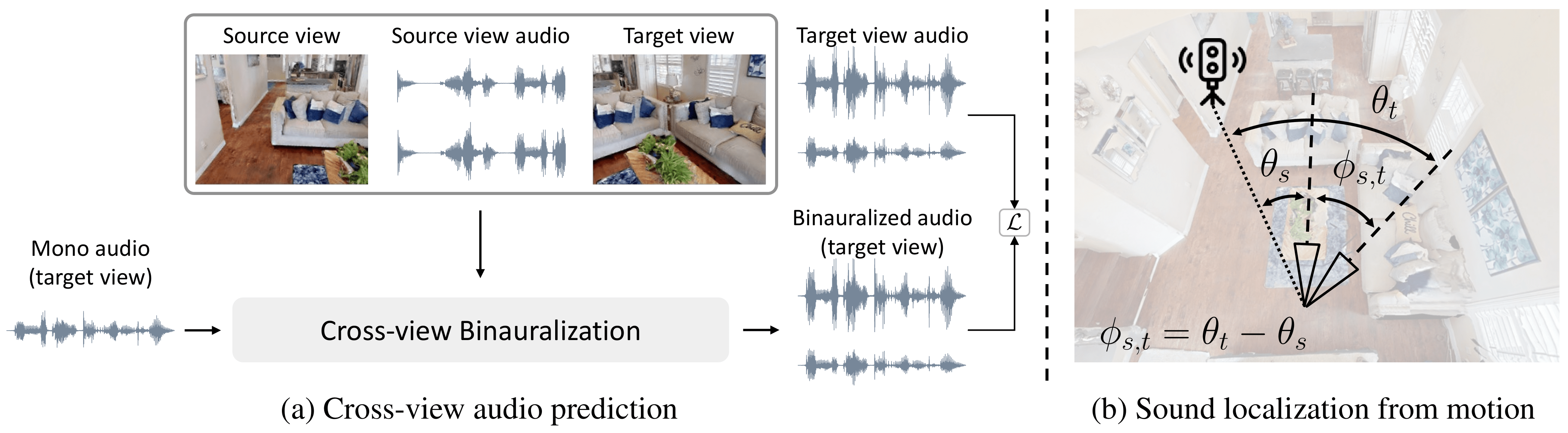
Our method consists of two parts: (a) Cross-view audio prediction for repesentation learning; and (b) Sound localization from motion: jointly esimating sound direction and camera rotation.
Learning representation via spatialization
We first learn a feature representation by predicting how changes in images lead to changes in sound in a cross-view binauralization pretext task. We convert mono sound to binaural sound at a target viewpoint, after conditioning the model on observations from a source viewpoint.
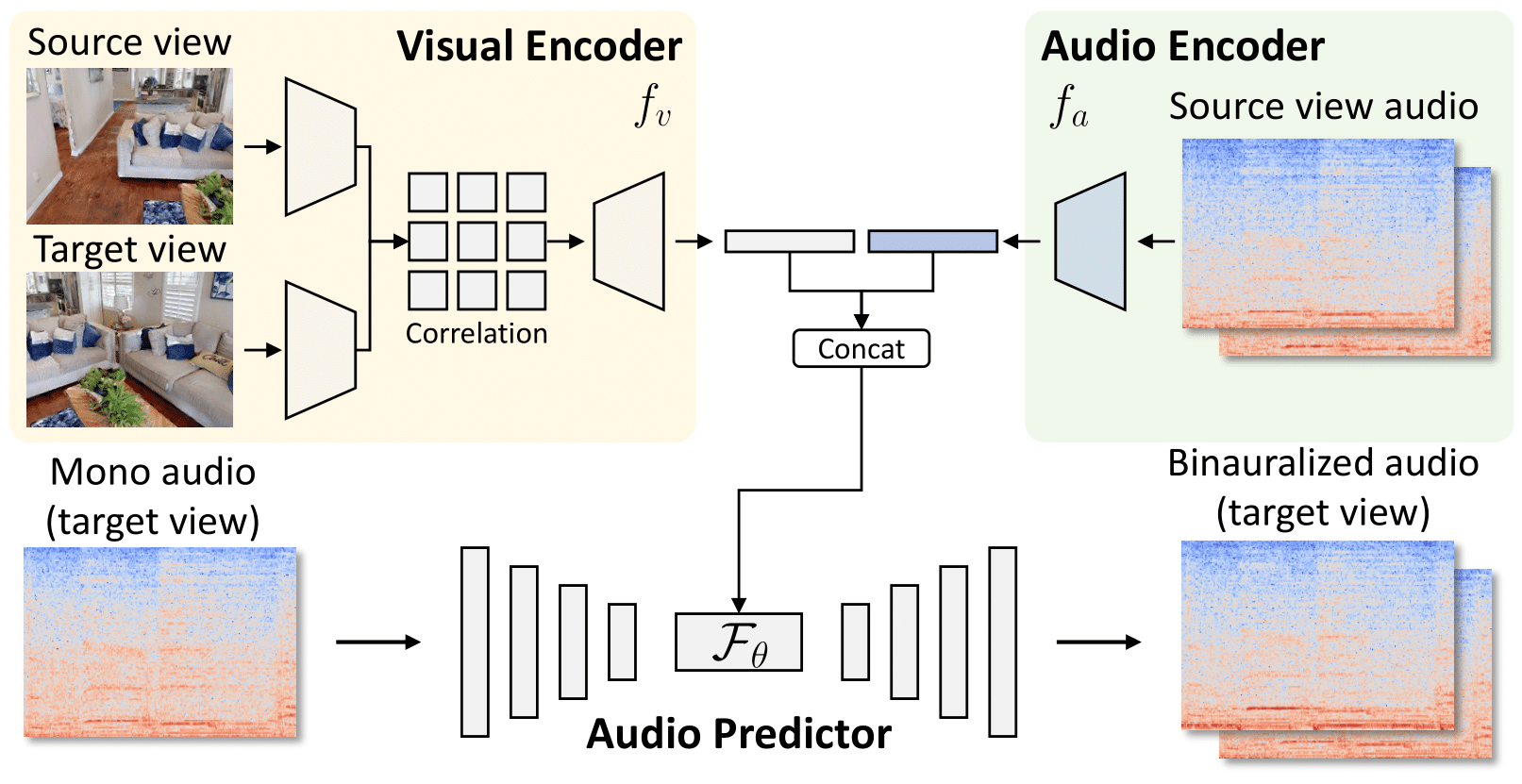
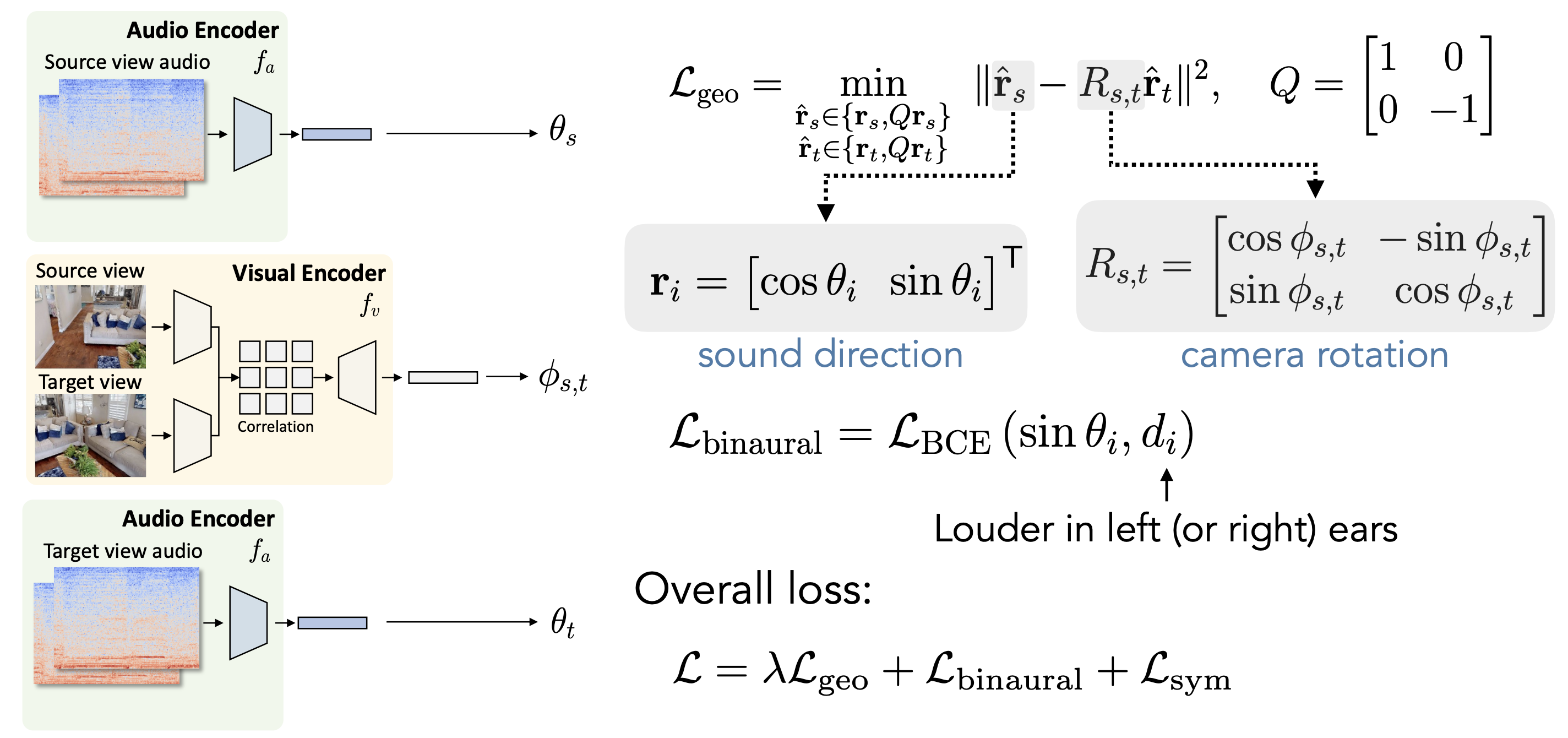
Estimating pose and localizing sound
We use the representation to jointly solve two pose estimation tasks: visual rotation estimation and binaural sound localization. We train the models to make cross-modal geometric consistency that visual rotation angle, \(\phi_{s,t}\), to be consistent with the difference in predicted sound angles \(\theta_s\) and \(\theta_t\): \[ \text{geometric consistency: } \phi_{s,t} = \theta_t- \theta_s\]
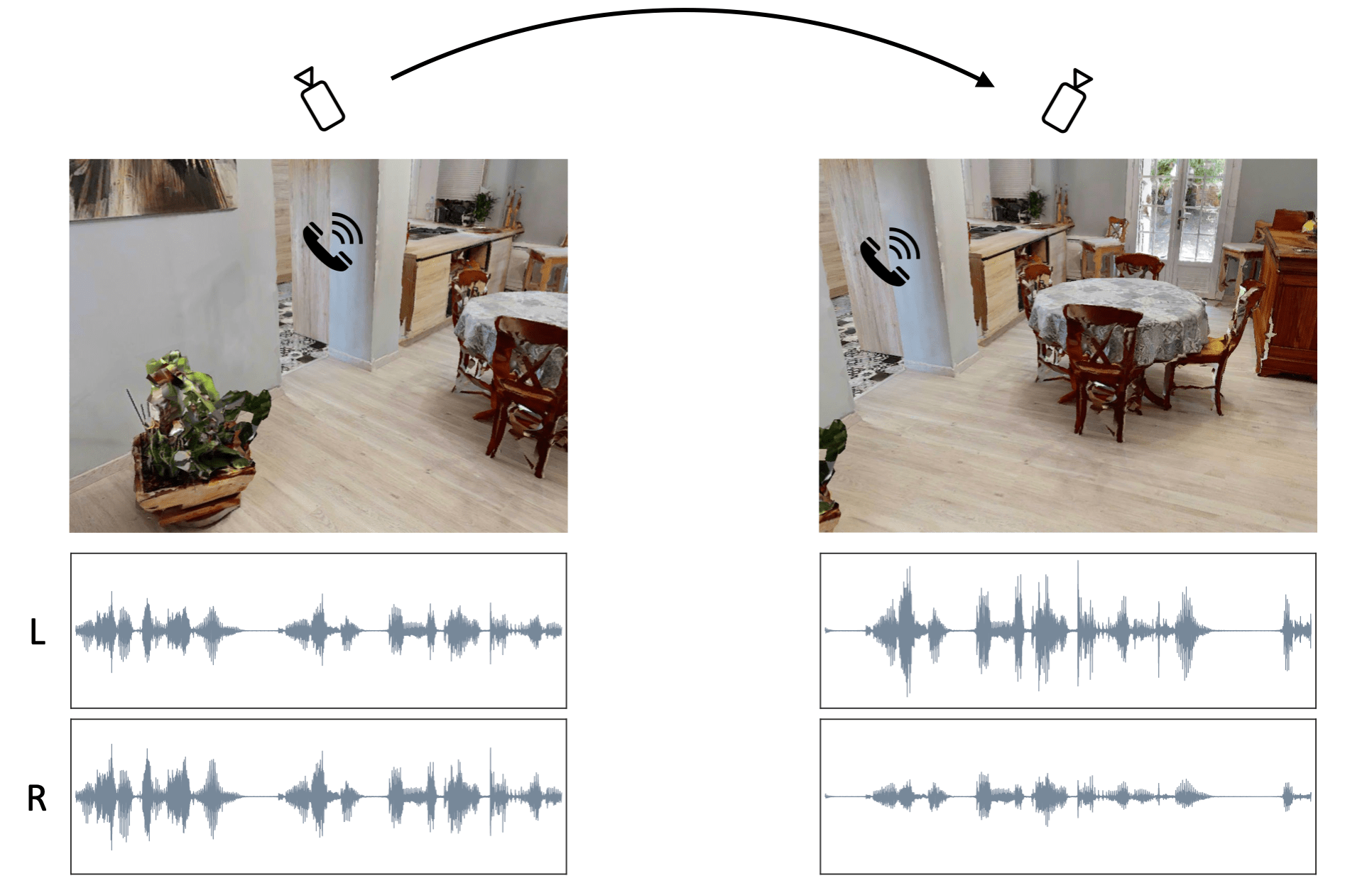
Qualitative Results
We show some qualitative results on both synthetic data and real-world videos recorded by us.
Qualitative predictions on simulated data
Real-world Demo
BibTeX
@inproceedings{chen2023sound,
title = {Sound Localization from Motion: Jointly Learning Sound Direction and Camera Rotation},
author = {Chen, Ziyang and Qian, Shengyi and Owens, Andrew},
journal = {International Conference on Computer Vision (ICCV)},
year = {2023},
url = {https://arxiv.org/abs/2303.11329},
}