|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
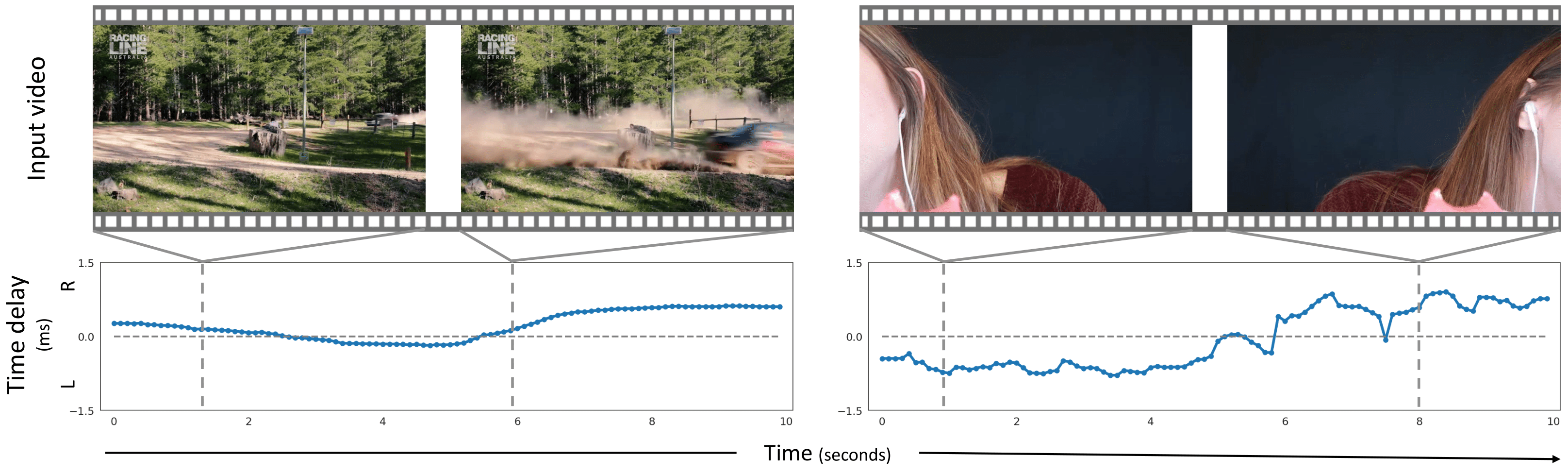
| Sounds in the world arrive at one microphone in a stereo pair sooner than the other, resulting in an interaural time delay that conveys their direction. Estimating a sound's time delay requires finding correspondences between the signals recorded by each microphone. We propose to learn these correspondences through self-supervision, drawing on recent techniques from visual tracking. We adapt the contrastive random walk of Jabri et al. to learn a cycle-consistent representation for binaural matching, resulting in a model that performs on par with supervised methods on "in the wild" internet recordings. We also propose a multimodal contrastive learning model that solves a visually-guided localization task: estimating the time delay for a particular person in a multi-speaker mixture, given a visual representation of their face. |
|
|
|
|
In-the-wild video results |
Visually-guided time delay estimation |
|
|
|
Binaural car demo |
iPhone video demo (Video Credits) |
|
|
|
 |
Ziyang Chen, David F. Fouhey, Andrew Owens. Sound Localization by Self-Supervised Time Delay Estimation. arXiv 2022. (Arxiv) |
Acknowledgements |
