Method
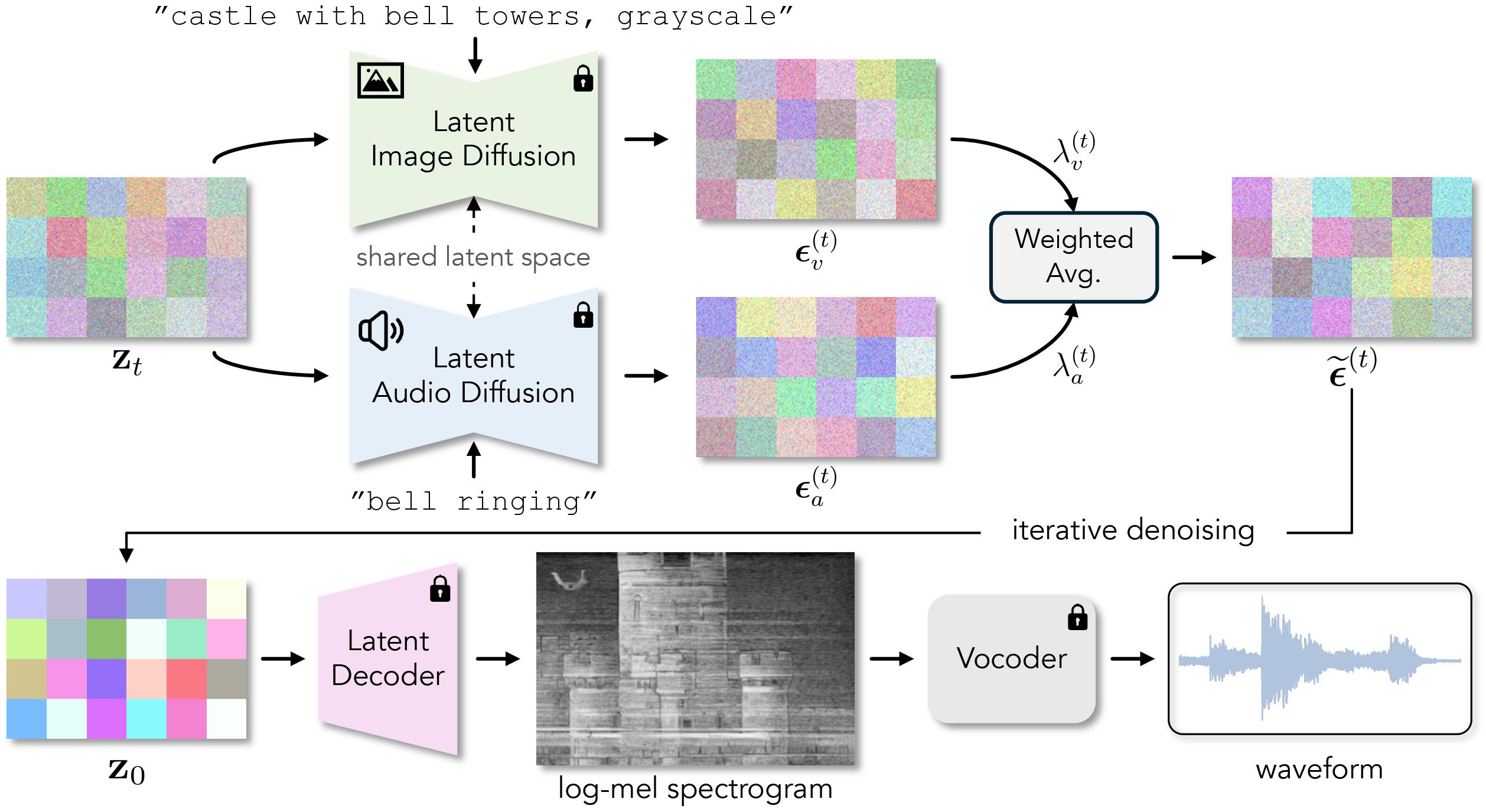
We pose the problem of generating images that sound as a multimodal composition problem: our goal is to obtain a sample that is likely under both the distribution of images and the distribution of spectrograms. To do this, we simultaneously denoise using an image diffusion model and an audio diffusion model. Given a noisy latent \(\mathbf{z}_t\), we compute two text-conditioned noise estimates \(\boldsymbol{\epsilon}_{v}^{(t)}\) and \(\boldsymbol{\epsilon}_{a}^{(t)}\). One for each modality. We then obtain a multimodal noise estimate \(\tilde{\boldsymbol{\epsilon}}^{(t)}\) via weighted averaging, which we then use to denoise. Repeating this process iteratively results in a clean latent \(\mathbf{z}_0\). Finally, we decode this clean latent to a spectrogram and convert it into a waveform using a pretrained vocoder. As we only change the inference time procedure, our method is zero-shot, requiring no training or fine-tuning.
Iteratively denoising using both a spectrogram diffusion model and an image diffusion model. See above for videos with sound.